This is part two of a three-part series on machine learning in Rust. Find the first part here. In this part, we discuss what the Rust machine learning ecosystem has to offer: what crates exist, what they can do, and a bit on how to use them.
We’ll see that, while there is no comparison with the tools available in Python, there is already tremendous activity in this space. In fact, it is already quite usable for our use case of deep Q-learning.
This discussion is by no means intended to be comprehensive. I’m focusing on just a few crates. For a more complete resource on machine learning crates, see the website arewelearningyet.com.
What do we need?
Our strategy requires training and inference for neural networks. We want to be able to define, train, persist, retrieve, and infer from models. What’s more: reinforcement learning is a bit “unusual”. The technique of exponential moving average requires us to manipulate models directly in ways which don’t occur with regular supervised learning.
We’d also prefer a “Rust-native” solution which does not depend on any system-installed libraries. Depending on external libraries complicates the build process, especially when cross-compiling. It also pretty much rules out support for WebAssembly.
Finally, it would be great to support GPU-accelerated training.
As we will see, these requirements already substantially restrict our selection.
The big players: TensorFlow and PyTorch
The two heavyweights in deep learning are TensorFlow from Google and PyTorch from Meta. Both have a C++ core library with a Python API. The Rust crates tensorflow and tch provide safe bindings of the C++ libraries. Thus one can access much of their functionality from Rust.
This approach is problematic already because of the dependency on C++ libraries. Just for this reason, I’d rather use these only if there is no other choice.
The TensorFlow bindings in particular appear to be underdeveloped. It is not clear whether, or how, one can build a model directly in Rust. All examples in the crate repository rely on loading existing persisted models. What’s more: the API is based on the old TensorFlow 1.x API rather than the newer keras API used in TensorFlow 2.x.
Trying to use TensorFlow in Rust, I found myself going down a rabbit hole. I decided to move on from TensorFlow and PyTorch and to look for a Rust-native solution for deep learning. Fortunately, there are some really compelling Rust-native solutions.
Rust-native deep learning: dfdx and burn
The crates dfdx and burn are Rust-native libraries for deep learning. They both support creating, training, inferring from, persisting, and loading deep learning models.
dfdx
The dfdx crate offers an API similar to that of PyTorch. One defines a model as a Rust tuple with the operations each layer performs:
type MyModel = (Linear<9, 32>, ReLU, Linear<32, 32>, ReLU, Linear<32, 9>);
The training loop itself is fairly low-level. One allocates gradients which will store the gradient of the trainable parameters based on the loss function. Then one runs the model forward on the input to calculate the inferred output and track the parameters needing gradients. One then runs the model backward with the calculated loss in order to calculate the gradient value for each trainable parameter. Finally, the optimiser updates the trainable parameters.
type Device = Cpu;
type EntryType = f32;
fn train(
model: &mut MyModel::Built,
input: &Tensor<(usize, Const<N_FEATURES>), EntryType, Device>,
output: &Tensor<(usize, Const<N_ACTIONS>), EntryType, Device>,
optimiser: Adam<MyModel::Built, EntryType, Device>,
) {
// Allocate a set of gradients to be calculated on each training iteration.
let mut gradients = model.alloc_grads();
for _ in 0..TRAIN_STEPS {
// Pass forward through the model to obtain the predicted value.
let predicted = model.forward_mut(input.trace(gradients));
// Compute the loss by comparing the predicted and actual output values.
let loss = mse_loss(predicted, output.clone());
// Use backward propagation to calculate the gradients of the parameters wrt. the loss function.
gradients = loss.backward();
// Update the model by adjusting the parameters against the calculated gradients.
optimiser
.update(&mut model, &gradients)
.expect("Unused parameters found");
// Clear the gradients for the next iteration.
model.zero_grads(&mut gradients);
}
}
GPU-accelerated training and its implications
The dfdx crate supports GPU-acceleration through the CUDA library. One chooses which backend dfdx
uses – CPU or CUDA – through the Device type in the code above. Unfortunately, the CUDA API is
proprietary and only available with Nvidia hardware. One cannot access it through, say, a browser
application running in Web Assembly.
There is work in progress for a WGPU backend for dfdx. That would allow the use of any GPU, or even training and inference from within a web browser.
Support for GPU-acceleration has some interesting implications. The GPU is a separate computing unit with its own memory. This implies:
- All operations on the GPU – in particular, all training and inference computations – are asynchronous.
- Extracting data from GPU memory so that they are accessible from the CPU is an expensive operation. One therefore tries to hold the model in the GPU and avoid accessing them from the CPU.
The API is structured to appear synchronous, but its internal design supports asynchronous operations. Invoking a training loop merely queues up the requested operations. The library only blocks at points where the model or its inferences are made explicitly accessible outside the crate itself. For example, retrieving the result of inference and persisting the model block on the completion of queued operations and data retrieval.
This has implications in how one can manipulate the model directly. It is intentionally difficult to directly access model parameters. Instead, one must express every manipulation in terms of pre-defined operations for which the required GPU kernels have been implemented. The following example implements the exponential moving average updating logic mentioned above.
const TAU: f32 = 0.9;
type Device = Cpu;
type EntryType = f32;
struct Updater;
impl TensorVisitor<EntryType, Device> for Updater {
type Viewer = (ViewTensorRef, ViewTensorRef);
type Err = <Device as HasErr>::Err;
type E2 = EntryType;
type D2 = Device;
fn visit<S: dfdx::shapes::Shape>(
&mut self,
_: TensorOptions<S, EntryType, Device>,
(model, model_training): <Self::Viewer as TensorViewer>::View<'_, Tensor<S, EntryType, Device>>,
) -> Result<Option<Tensor<S, Self::E2, Self::D2>>, Self::Err> {
let mut model = model.clone();
model.axpy(TAU, model_training, 1.0 - TAU); // model <- TAU * model + (1 - TAU) * model_training
Ok(Some(model))
}
}
model = TensorCollection::iter_tensors(&mut RecursiveWalker {
m: (&model, &model_training),
f: &mut Updater,
}).unwrap().unwrap();
Fortunately, the crate already provides built-in support for exponential moving average. The following is essentially equivalent to the code above:
const TAU: f32 = 0.9;
model.ema(&model_training, TAU); // model <- TAU * model + (1 - TAU) * model_training
The upshot on dfdx
The dfdx crate is already quite powerful and offers essentially all the functionality we need. The only drawback for my purposes is the current lack of support for WGPU as a backend. Hopefully that limitation will be resolved in the future. All in all, dfdx is a solid choice for deep learning.
Burn
Burn is a relatively new player in the Rust machine learning ecosystem. It includes support for GPU-acceleration through both the CUDA and WGPU APIs.
Its API is quite high-level in comparison with dfdx. Rather than writing the training loop in terms of moving forwards and backwards through the model, one configures a learner and just tells it to fit the model to the training data. In that respect, it resembles the TensorFlow Keras API.
let config = MyConfig { num_epochs: 100, ... };
let device: Cpu = ...;
let input_dataset = InMemDataset::new(input.clone());
let batcher = DqnBatcher::new(device.clone());
let dataloader_train = DataLoaderBuilder::new(batcher)
// Some configuration...
.build(input_dataset);
let dataloader_test = // More of the same...
let learner = LearnerBuilder::new("models")
// Some more configuration...
.devices(vec![device.clone()])
.num_epochs(num_epochs)
.build(model.clone(), optimiser.init(), learning_rate);
learner.fit(dataloader_train, dataloader_test);
Burn offers some interesting visualization of the training right out of the box:
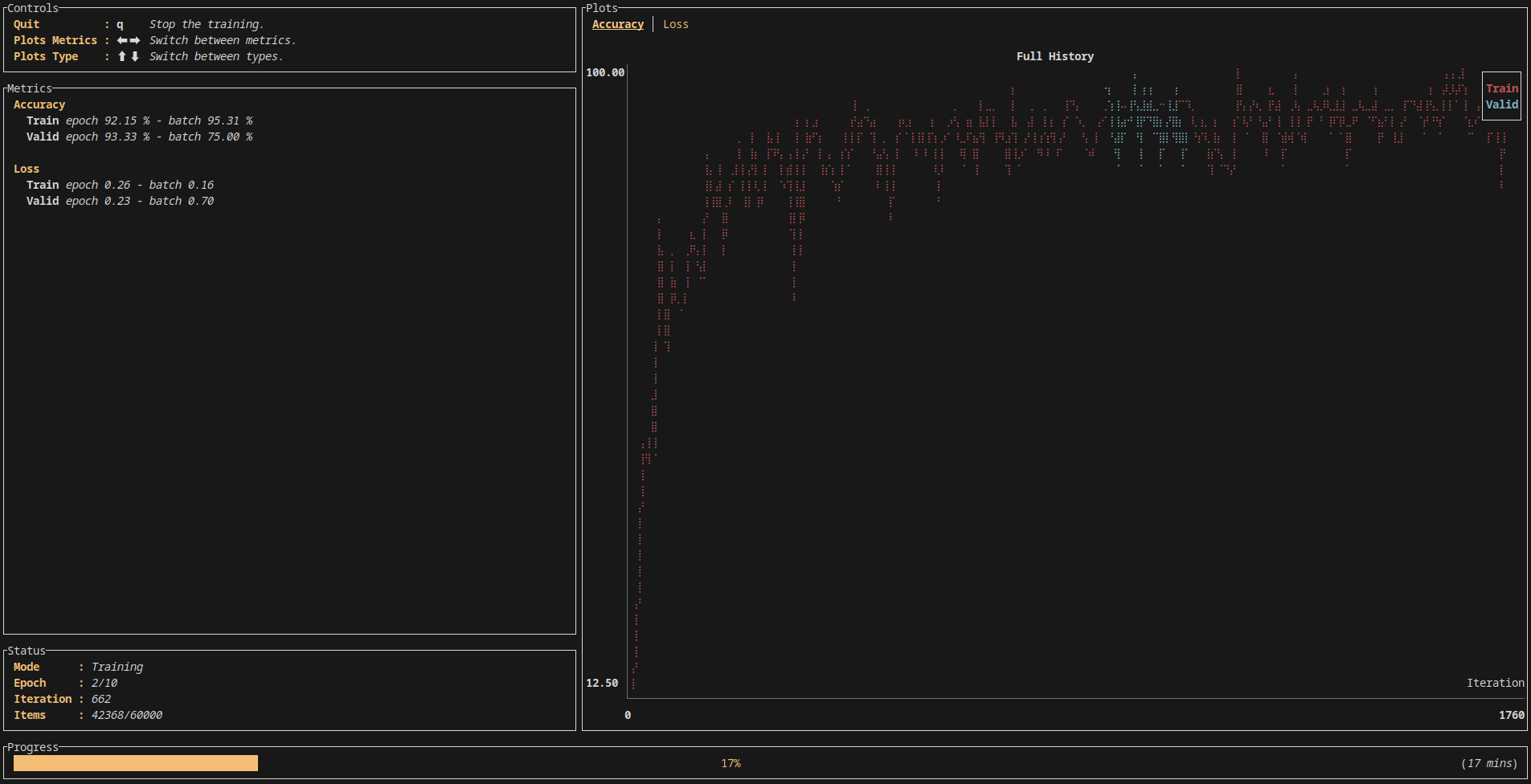
Unfortunately, Burn’s higher level API does not allow for the kinds of lower-level manipulations of the model we need. In particular, there is (as of the time of writing) no support for exponential moving average. While Burn is a promising alternative for supervised deep learning, it falls short when applied to reinforcement learning.
Rust-native reinforcement learning with rurel
No discussion of reinforcement learning in Rust would be complete with a mention of rurel, a crate specifically for reinforcement learning in Rust.
Rurel has a fairly straightforward architecture. One defines a game by implementing the traits
State and
Agent. These define the game state and
how actions affect that state, respectively. The trait
LearningStrategy
encapsulates the reinforcement learning algorithm.
Rurel comes with a simple Q-learning implementation. The caller supplies a hash map which stores the values of the action-value function for examples which have been seen before. Unlike neural networks, this type of model cannot generalize from known to unknown states. If it has not seen a state yet in an example, then it cannot deduce anything about the best action.
Rurel does not include any native support for training and inference with neural networks. There is an experimental bridge between rurel and dfdx. However, it does not provide the level of control we need to experiment fully in this space. Thus I did not use rurel in these experiments.
Conclusion
I tried out various solutions and settled on dfdx in the end. It has a relatively straightforward API with everything one needs for basic reinforcement learning. While it currently lacks WGPU support for GPU-accelerated machine learning, that support is in the works. All in all, dfdx provides the right balance for this project.
The Rust machine learning ecosystem is surprisingly well-developed. It’s especially interesting that there are two well-developed Rust-native crates specifically for deep learning. It’ll be interesting to see how the Rust machine learning ecosystem develops.