This is the last of a three-part series on machine learning in Rust. Find the first part here and the second part here. In this part, I will show some experimental results I obtained trying out the techniques I have discussed.
The goal of a game AI is to lose the game.
– A paper I read once
My goal in starting out on this journey was to try to build a computer player AI for a game in Rust. The point of such an AI is to make the game interesting and enjoyable for the human player. The gameplay should feel plausible. In particular, the gameplay should not be perfect. The computer player would then be practically unbeatable, which does not make for an enjoyable game.
A simple example
I started experimenting with the game of Tic-Tac-Toe. It is an adversarial game, like the strategy game I ultimately want to implement. The gameplay is so simple that it makes for an easy testbed. At the same time, it is nontrivial enough to obtain interesting results.
I use a neural network with two hidden layers, each of 32 neurons, to model the action-value function. The input state is a vector of nine elements corresponding to the nine locations on the grid. A value of +1.0 represents the spot being occupied by the player being trained, -1.0 the opponent, and 0.0 an empty spot. The only action is to place a piece on an existing empty spot, so the action is a one-hot encoded vector of length 9.
graph LR S[Game state\n9 inputs] --> H1[Hidden layer\n32 neurons] H1 --> H2[Hidden layer\n32 neurons] H2 --> A[Action weights\n9 outputs]
We assign a reward of +100 for a won game, -100 for a loss, and -10 for a draw. Intermediate states all have a reward of 0. The strategy takes the action with the highest estimated value in each turn.
I trained the “O”-player and used the “X”-player as an adversary. This is because the “O”-player has a natural disadvantage, so the results would be more expressive.
In each training round, the player being trained plays 200 games against each of an untrained actor and the previous version of itself. The untrained actor essentially picks a random move on each turn.
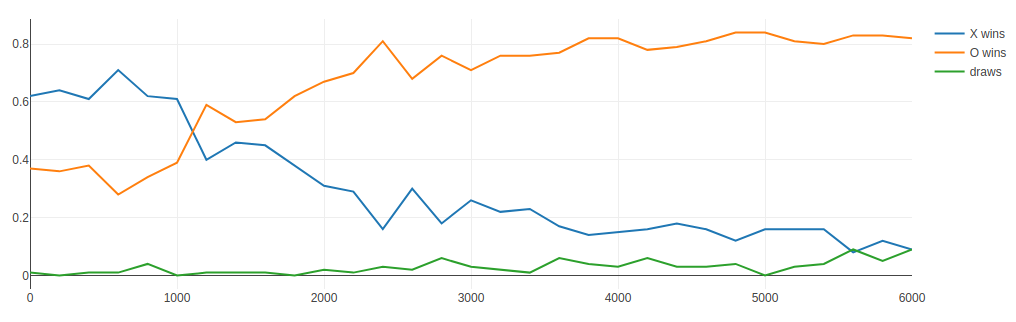
After each training round, I evaluate the model’s performance by running 100 games against a completely untrained actor. The graph below shows the portion of each game outcome during evaluation vs. the total number of training games played:
Some observations
The graph above shows that the deep Q-learning method “works” in the sense that the agent does improve over time, at least for roughly the first 4000 training games. A totally naive agent playing as “O” wins about 40% of the time against a naive “X” opponent. It remains “dumb” for roughly the first 1000 games. During this time, it is naively exploring the state space and encountering its first rewards through luck alone.
After that, the model learns enough that it can exploit obvious winning moves in at least some cases. Its win rate against a naive agent then rapidly increases, but eventually levels off at about 80%. The rate of draws also increases slightly.
When playing against a human, the model seems fairly lacking. The following screencast shows me playing as “X” against a trained computer AI model “O”. The computer player can win, but only if I make really obvious mistakes. It has not learned how to “corner” the “X” player to force a win, nor to consistently block me.
One might say that the gameplay feels somewhat “natural” but not particularly smart.
Looking at the action-value function
We can examine what the action-value model produces more closely to see where the model isn’t quite good enough. Take the following position from one of the games played above, for example:

The O player can clearly win in just one move by placing a piece at the third row, second column. But instead, it places a piece at the second row, third column:

The chosen move makes no sense. Not only did the player not take the opportunity to win immediately, it failed to block its opponent from winning by placing a piece at the third row, first column.
Let’s look at what the model says the action-values are for the first position above:
So it’s clear why the agent picks the move it does. The model is deathly afraid of both of the moves which make sense!
Conclusion
Clearly there is more territory to cover on this journey. While the model has learned to recognize some winning and blocking moves, it cannot do so consistently. As we have seen, model performance plateaus after about 3000 training games. So it does not appear just to be matter of seeing more states.
Will this approach lead to a reasonable computer player AI? It’s going to take a lot more experimentation to find out. But that’s where the fun begins!
You can find my experiments on GitHub.